
INTRODUCTION
Our project is a Japanese OCR for manga! We take manga text bubbles, segment characters into subimages, classify each subimage into machine-readable characters, and combine characters into sentences. We can even translate entire sentences to English with a simple API call. The user will be able to highlight the text boxes themselves to reduce the complexity of our project.
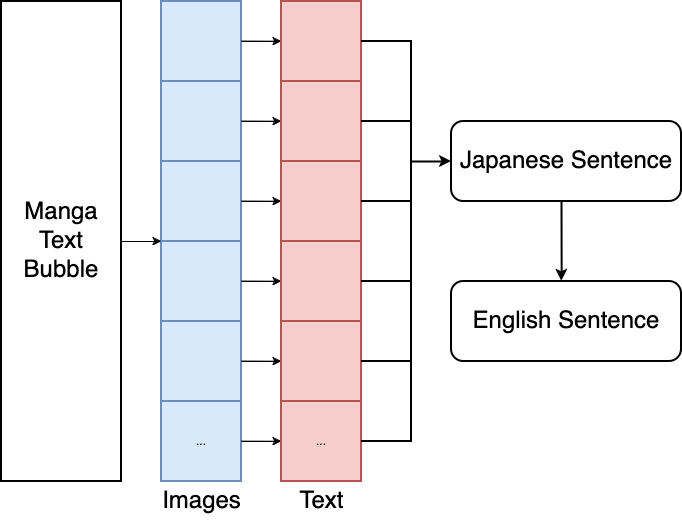
Fig 1. Our proposed implementation
LITERATURE REVIEW
Optical character recognition (OCR) is a field of ML that focuses on extracting text from images to machine-readable text (i.e. UTF=8). OCR has a number of classification methods, including artificial neural networks, Kernel methods, statistical methods, template matching techniques, and structural pattern recognition [1].
Manga109 has been used to train an AI model to recognize and retrieve a manga based on a user’s sketch of a character or panel contained within. This is not entirely relevant to OCR, but they do outline good image processing methods for Manga109 data [2].
Character classification is a central part of our project. There are multiple thousand unique kanji, and some kanji may not even be present in our dataset. A team has achieved a 48% accuracy on zero-sampled kanji by deconstructing kanji into radicals and using a ResNet model to feature extract [3].
DATASETS
Manga109: A dataset of 109 manga which are annotated with face, body, character, and (importantly for us) text.
CC-100: A collection of datasets for constructed sentences of multiple different languages, scraped from the internet, including Japanese which we will use to create samples.
KMNIST: Three datasets that organize Japanese Cursive, which is very diverse and oftentimes dissimilar to modern writing.
KanjiVG: A list of vector graphics which gives information about strokes and stroke order corresponding to Japanese Kanji.
PROBLEM DEFINITION
PROBLEM
The problem is to extract text from manga.
MOTIVATION
Learning Japanese is extremely difficult for native English speakers. Our project aims to convert manga images to machine-readable text so that Japanese learners can easily query for words.
METHODS
DATA PREPROCESSING
There are a ton of things we can do to preprocess the data. I assume our solution will involve some combination of the methods below.- Grayscale: cv2.cvtColor()
- Thresholding: cv.threshold()
- Edge detection: cv2.Canny()
- Contour detection: cv.findContours()
- Synthetic data generation using CC-100 and popular Japanese fonts
ML ALGORITHMS/MODELS
- CNN for Character Classification
- DBSCAN for Character Segmentation
- Google's Tesseract
- Vision Encoder Decoder Transformer
RESULTS AND DISCUSSION
QUANTITATIVE METRICS
- Character Error Rate
- Word Error Rate
- F1 Score averaged across character classes
PROJECT GOALS
We aim to have this project up on our website, and our main goal is for good user experience which is hard to quantify with a metric.
EXPECTED RESULTS
We don't expect perfect results as good OCR is a real pain. We did a small proof-of-concept with Google's Tesseract model, and it's not very good. Despite this, Google's model is for any language and any format, so there could be things we do in our project which leverages some features of manga to get better results.
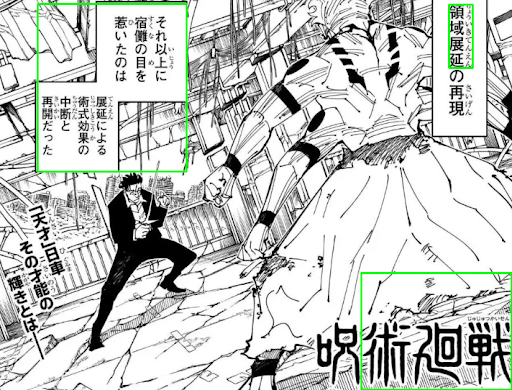

Fig 2. Naive Implementation with Google's Tesseract
REFERENCES
[1] J. Memon, M. Sami, R. A. Khan, and M. Uddin, ‘Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR)’, IEEE Access, vol. 8, pp. 142642–142668, 2020.
[2] Aizawa Yamasaki Matsui Lab, “Manga109: Japanese Manga Dataset.” Accessed Sep. 27, 2024. [Online]. Available: http://www.manga109.org/en/annotations.html
[3] T. Ishikawa, T. Miyazaki, and S. Omachi, ‘Japanese historical character recognition by focusing on character parts’, Pattern Recognition, vol. 148, p. 110181, 2024. doi: 10.1016/j.patcog.2023.110181
GANTT CHART
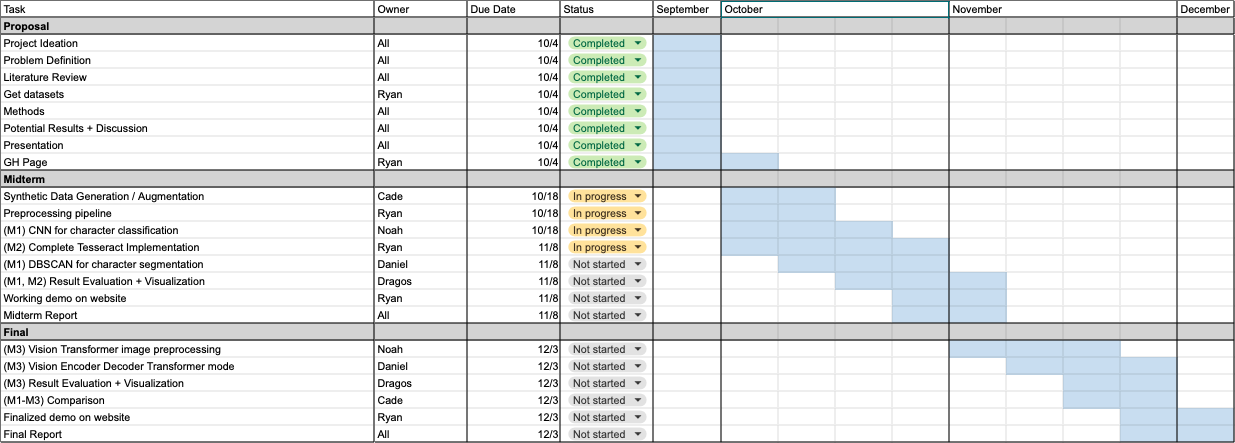
Fig 3. Gantt Chart
CONTRIBUTION TABLE

Fig 4. Team Contribution Table
PRESENTATION
Fig 5. How to center a div