
INTRODUCTION
Our project is OCR for Japanese manga! We take manga text bubbles, segment characters into subimages, classify each subimage into machine-readable characters, and combine characters into sentences. We can even translate entire sentences to English with a simple API call. The user will be able to highlight the text boxes themselves to reduce the complexity of our project.
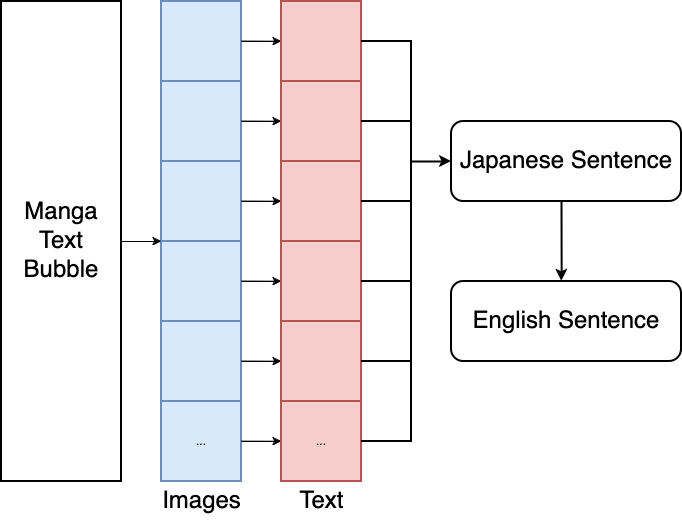
Fig 1. Our proposed implementation
LITERATURE REVIEW
Optical character recognition (OCR) is a field of ML that focuses on discerning information about characters encoded in a non-traditional format (ex. not UTF-8), such as in images, by using pattern and feature discrimination and classification [1]. OCR has a number of classification methods, including artificial neural networks (feedforward networks, recurrent neural networks, convolutional neural networks), Kernel methods (support vector machines, Kernel Fisher discriminant analysis, Kernel principal component analysis), statistical methods (logistic regression, linear discriminant analysis, hidden Markov models, K nearest neighbors, decision trees), template matching techniques, and structural pattern recognition (chain code histogram) which typically depend on large datasets with enough character variety to allow for “a meaningful comparison” [1]. The dataset being considered for the problem of OCR for Japanese manga is Manga109, which contains sets of manga pages and accompanying annotations for elements within, such as characters’ names and, more importantly, the text for the speech bubbles [2]. Manga109 has been used to train an AI model to recognize and retrieve a manga based on a user’s sketch of a character or panel contained within by using an objectness-based edge orientation histogram, approximate nearest neighbor search methods, image processing techniques, and more [3].
Binarization is a main step in the processing part of OCR, where an image is turned into a binary image that contains only black and white pixels. This is done through finding a threshold that will make the pixels with an intensity higher than it turn to white pixels and the other pixels turn to black removing much of the noise that comes in images. Following this step is the deskewing step in which the new binary image is projected horizontally creating a histogram. This histogram is then rotated at different angles to calculate the variance and then find the angle with the greatest variance, after identifying that angle the image is then deskewed by rotating the image by that angle [4]. Morphology is a technique that analyzes structures within an image and this is used to isolate characters and determine what direction each line of text is meant to be interpreted from then it removes any parts that are not a part of the characters and rearranges the new simplified characters back into the text lines in the correct direction [5].
Tesseract OCR Engine is an optical character recognition system that integrates advanced techniques in connected component analysis, line and word segmentation, and adaptive classification delivering high-accuracy text recognition results [6].
Residual Network, or ResNet, is a deep learning architecture in which the weight layers learn residual functions with reference to the layer inputs. It has won the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) 2015 in image classification, localization, and detection. One of the reasons why it won was because it managed to tackle several issues that the plain networks had. Several issues that the plain networks had were when its network was deeper or the layers increased, gradients would explode or vanish. This occurs during backpropagation where it multiplies the number n of these small (vanish) or large (explode) numbers to compute gradients of the front layers in a n-layer network. The way that ResNet handled this problem is by using the skip shortcut connection that allows it to fit the input from the previous layer to the next layer without having to modify the input. Even if a vanishing or exploding gradient takes place, it always has the identity x to transfer back to earlier layers [7]. Shortcut connections simply perform identity mapping and their outputs are added to the outputs of the stacked layers. They add neither extra parameter nor computational complexity [8]. This would be a great character classification model for our OCR implementation because of how it prevents gradients from exploding or vanishing. This allows the character classification learning to become more efficient, be able to extract relevant features, and better generalize to new characters. Being able to handle variability in characters is crucial because it must distinguish between two characters that look almost identical but aren’t the same. If that problem was not addressed, the character classification accuracy wouldn’t improve that much and would have a higher validation error.
Vision Transformer (ViT) is a model that applies Transformer architecture to image recognition tasks, facilitating the integrating of global information through self-attention mechanisms. Its high computational efficiency makes ViT a great model to use for OCR where both accuracy and processing speed are critical. Furthermore, when combined with Convolutional Neural Networks (CNNs) such as ResNet to form a hybrid architecture, the resulting hybrid model achieves a higher accuracy than using either ViT or ResNet independently [9]
DATASETS
Manga109: A dataset of 109 manga which are annotated with face, body, character, and (importantly for us) text.
CC-100: A collection of datasets for constructed sentences of multiple different languages, scraped from the internet, including Japanese which we will use to create samples. This allow class frequency for character classification be naturalistic.
Fonts: We downloaded 63 free fonts which are most likely to resemble fonts in Japanese manga.
PROBLEM DEFINITION
PROBLEM
The problem is to extract text from manga in the browser.
MOTIVATION
Learning Japanese is very hard (source: Noah and Ryan). One of the best ways for second language acquisition is through immersion and to pair this with daily rote memorization (typically through something like Anki). One of the best ways to study Japanese naturally is with a tool called Yomitan, a browser extension equipped with a Japanese-to-Japanese dictionary, a Japanese-to-English dictionary, and support for automatic Anki card generation. While it's rather easy to find free Japanese media online, it's very hard to extract text so that learners can use Yomitan. Our project aims to convert Manga images to plaintext such that this tool can be used in the browser.
METHODS
Our working implementation is with Google's OCR Engine, Tesseract. We preprocess text bubbles from the Manga109 dataset then use Tesseract to convert the images into machine-readable text.
DATA PREPROCESSING
Manga speech bubbles are quite noisy. The pages may be off-white and the background in the manga could be included in our text bubble images. Preprocessing serves as a way to extract the most salient information (the characters) from the image. We have a preprocessing pipeline which does following:
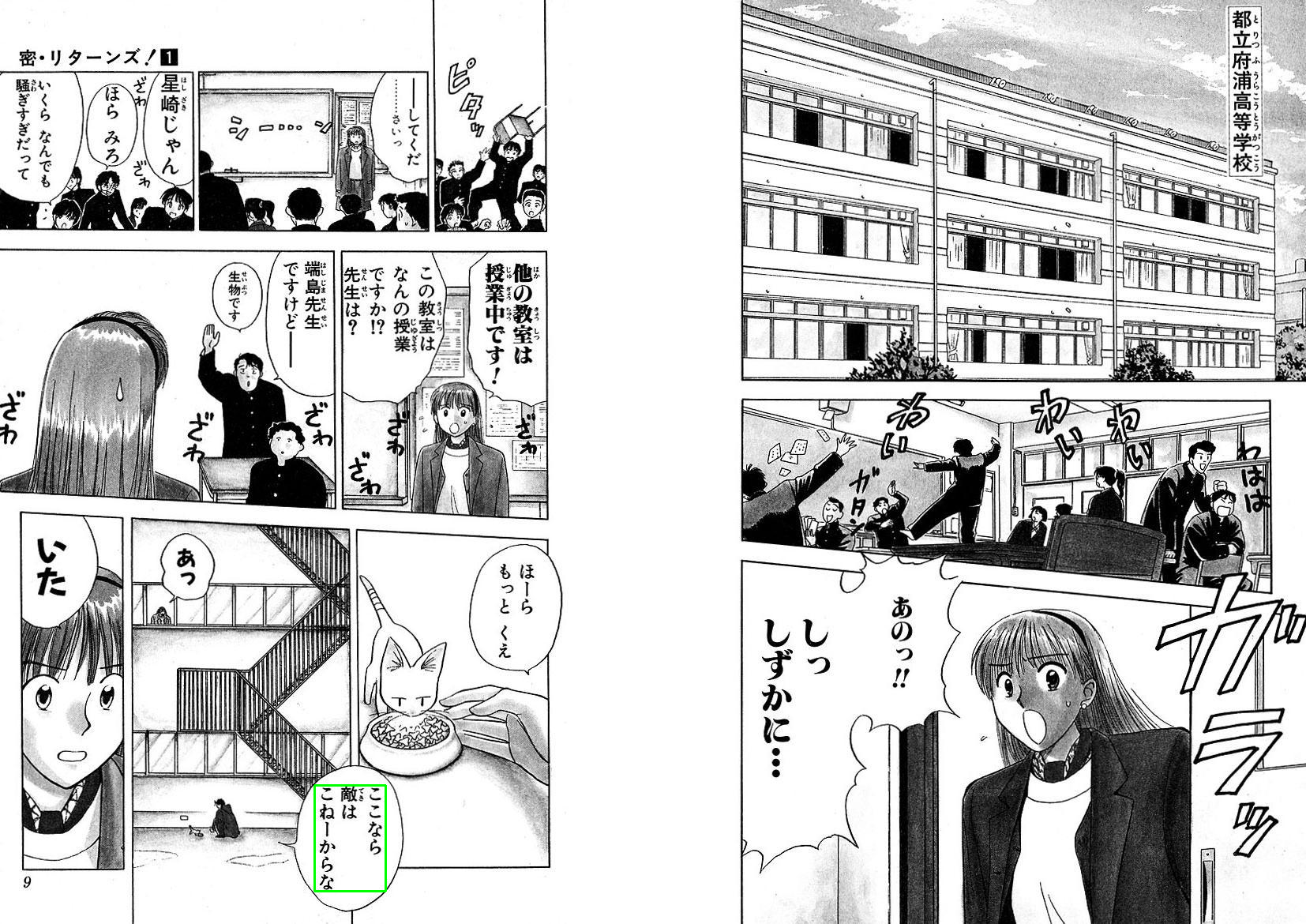
Image Source: "Hisoka Returns!" from the Manga109 dataset. Courtesy of Yagami Ken. Annotated textbox is highlighted in green.
Scale the image up: When the image is too small, future preprocessing could be too extreme. For example, when performing morphological operations, a 2x2 kernel could be too big and a 1x1 kernel literally doesn't do anything. The problem is that we cannot have a 1.5x1.5 kernel. We could mimic this behavior by doubling the size of the image, then using a 3x3 kernel. Furthermore, a lot of the text in Manga109 is very small! We found this helps results dramatically. We invert the color as well because opencv expects white text on black background for morphology.

Image thresholding: Operating on a binary black and white image is a lot easier than a colored image. This makes detecting characteristics of the image easier for our preprocessing.
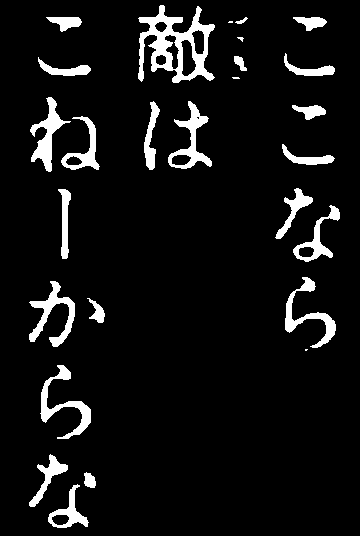
Morphology: We apply morphology onto the images to denoise. There are various artifacts in the text bubbles (either originally there, or as a result from scaling) which may hurt performance of our models. We apply an opening morphological expression onto the image to isolate the characters and to remove stray pixels between characters.
Character segmentation: We segment the text bubble into subimages containing a single character. This reduces the complexity of inferencing regardless of model. We achieve this by making histograms for black pixel frequency along columns and rows. A higher frequency for a given range of columns indicates those columns contain a vertical line of characters. Within that line of characters, we generate a horizontal histogram to isolate each character. Since most characters can fit in the same box space, we find the “tallest” character, and use that height to determine where characters fit. This helps when grouping disjoint components of characters like こ.

Deskewing: We rotate the image a little bit then calculate a vertical histogram of black pixel frequencies. A cool fact about this ("I have a truly marvelous demonstration of this proposition which this margin is too narrow to contain"), the histogram which has the highest variance is properly aligned. We have implemented this but have not included it in our Tesseract implementation. For starters, we cannot find any examples of skewed in Manga109, but cannot verify its nonexistence since there are 147887 textboxes in the Manga109 dataset. Most importantly, it hurts performance in cases where the text bubble includes a background image. Example:

Image Source: "Hisoka Returns!" from the Manga109 dataset. Courtesy of Yagami Ken.
SYNTHETIC DATA GENERATION
CC-100 contains a large amount of data of Japanese text collected through web-crawling; while this is certainly helpful for what we need to do, it doesn’t quite fit the bill for our tasks at hand. To train our models, what we need are images and their labels (the text contained in the image). For example, if we have the character “夜” from CC-100, we don’t just want the text; we also want the image containing the character. For sentences and sections of text, we need something similar, but more representative of how manga contains text. That is to say, we need both sample sentences and sample images that look like manga text boxes. For example, given the text “とを肌で感じることが出来まし”, we would need it in an image as well, like so:

To accomplish this, the plaintext data from CC-100 was used to generate equivalent character images and sentence images. For the character images, every character in CC-100 was rendered into an image using a random Japanese text font found online. For sentences, a random range between 1 to 16 was used to determine the length of a “sentence” in CC-100, and these characters were then rendered into an image following the format found in manga (start top-left, write to bottom-right). For the Tesseract implementation, this data is a little too perfect, with character segmentation being extremely easy to accomplish because there is no noise present. As such, SVD image compression and/or a Gaussian noise generator was run on the images, creating results that look like the following:


Left: Gaussian noise. Right: Compressed with SVD then ran through Gaussian noise generator.
TESSERACT MODEL
We run the text bubble through our preprocessing pipeline then give Tesseract an image of each character. Our preprocessed character subimages are white text on black background, so we invert the subimages once more since Tesseract expects the opposite. We used weights found online which were generated by training on vertically aligned Japanese. We then configured Tesseract to increase performance on single character classification (these were all just parameters to the model). Tesseract generates a bounding box, a confidence score, and the text. We only accepted text which had over 30% confidence. We used Tesseract to classify characters and then combine all characters in reading-order to generate our predicted text for a given text bubble.
def get_params():
"""
Returns:
(string): Configuration for Tesseract model
"""
params = ""
params += "--psm 5 "
params += "--oem 3 "
params += r"--tessdata-dir ../lib/weights " # Weights found online
params += r"--loglevel DEBUG "
configParams = []
def configParam(param, val):
return "-c " + param + "=" + val
configParams.append(("chop_enable", "T"))
configParams.append(('use_new_state_cost', 'F'))
configParams.append(('segment_segcost_rating', 'F'))
configParams.append(('enable_new_segsearch', '0'))
configParams.append(('textord_force_make_prop_words', 'F'))
configParams.append(('textord_debug_tabfind', '0'))
params += " ".join([configParam(p[0], p[1]) for p in configParams])
return params
def detect_characters(img):
"""
Params:
img (np.array): preprocessed character subimage
Returns:
(string): predicted text extracted from character subimage
"""
return pytesseract.image_to_string(
img,
lang='jpn_vert', # Trained for vertical Japanese
output_type=pytesseract.Output.DICT,
config=get_params()
)
RESULTS
Metrics for string comparisons are non-trivial, especially when strings can be of different length. The metric we used is Levenshtein distance per predicted character. A Levenshtein distance is the number of operations (insert, delete, replace) to convert string A to string B. Here is an example on how to interpret this:
| Predicted Text | Actual Text | Levenshtein Distance per Character |
|---|---|---|
| "abc" | "abd" | 0.33 |
| "ab" | "abcd" | 1.00 |
We ran our model on all manga in the Manga109 dataset:
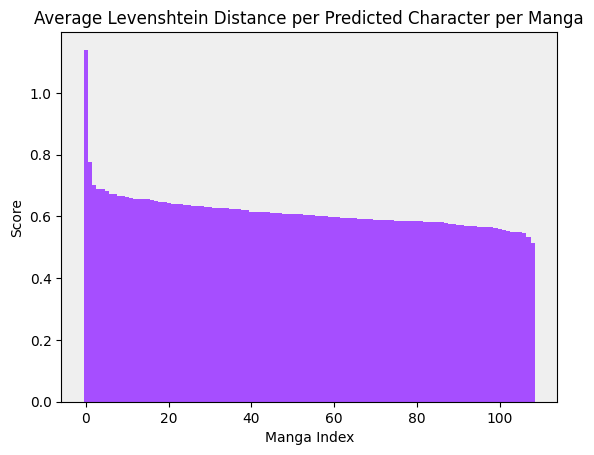
Fig 2. Tesseract model results on Manga109 dataset. Mean: 0.614. Standard Deviation: 0.064.
We also experimented with BLEU score, a popular metric for string-to-string comparisons. We found this metric is too volatile for our model since our model underguesses characters. BLEU score is calculated by comparing multiple n-grams, but since the predicted text is commonly shorter than the actual text and the textboxes don't contain much text, our BLEU score commonly shortcuts to 0. Example:
| Predicted Text | Actual Text | BLEU Score |
|---|---|---|
| 決めた 芸術だ | よし!決めた!!芸術だ!! | 0.00 |
The only thing meaningful text Tesseract did not predict was "よし". In English, the differences between these two strings are "It's decided it's art" and "Yeah! It's decided!! It's art!!", so a BLEU score of 0.0 seems too harsh.
DISCUSSION
On a whole, the Levenshtein distance had a mean of 0.614, which is clearly not an ideal score, but is workable as we tune Tesseract and improve our techniques; what is less workable is the fact that one manga had a Levenshtein distance greater than one. The culprit is a manga called Joouari, and the following is a panel from the manga:

Image source: "Joouari" from Manga109 dataset. Courtesy of Ooi Masakazu.
While it may be difficult to tell:

These three boxes are written differently than the other text boxes on the page, with text being written top-left to bottom-right. Previously, we specified that our training data would follow the standard paradigm of vertical writing present in manga, but ultimately, this does not account for left-to-right writing, and we did not account for this in the Tesseract implementation either. Upon further inspection, these sorts of text boxes were found throughout the manga, giving probable explanation as to why a Levenshtein distance over 1 was obtained. This manga also has very dense character blocks in its text boxes, many white-on-black text boxes (the expected is black-on-white), and other elements that could also contribute to this error.
NEXT STEPS
There are currently a lot of issues with how we are processing data, and a lot of areas where we can improve. Here is an example of a very common form of stylized writing which hurts the performance of our preprocessing pipeline.

Highlighted with green bounding box: kanji which spans multiple characters. Highlighted with red bounding box: furigana. Since Japanese kanji is not phonetic, furigana is common in Manga to show the reader how to pronounce some words. These do not add additional information and are less common in forms of media with older audiences.
Our segmentation is also far too specific. While the histogram method is working well, it doesn’t consider anything else when deciding where lines and characters appear. All we do is check if there’s no white pixels in a column and if there isn’t there's probably a column to the left and right. This means that Furigana may or may not be counted in a column, or (incredibly rarely) a column may be counted as two. Not to mention, we don’t consider horizontal or skewed Japanese at all.
We’re going to need significant changes in our algorithm to fix these issues, most of which will be based on the methods used in “Detection of Furigana text in images” [11]. First, rather than take in raw image data, we can first extract a text mask using the Manga Image Translator (MIT) [10]. We can then use DBSCAN to group areas of text, and distinguish between Furigana and the rest of the text, by size and shape. We can also distinguish between vertical and horizontal text in this step by their height/length ratio.
Then, once we have an image without Furigana, post deciding whether it’s vertical or horizontal, we can split the characters. Since length and width of a text box is the same, we should use width for a horizontal box, and width for a vertical one, because “long” characters wouldn’t span across lines. Then if a box’s edge happens to lie on an area with text, it’s probably a long character, so we can combine it with the next box, and then ignore both, or (incredibly theoretically, beyond our scope) apply the tone of the “long” character to wording.
REFERENCES
[1] J. Memon, M. Sami, R. A. Khan, and M. Uddin, "Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR)", IEEE Access, vol. 8, pp. 142642–142668, 2020.<\p>
[2] Y. Matsui, K. Ito, Y. Aramaki, T. Yamasaki, K. Aizawa. "Sketch-based Manga Retrieval using Manga109 Dataset." CoRR, vol. abs/1510.04389, 2015. doi: 10.1007/s11042-016-4020-z<\p>
[3] Aizawa Yamasaki Matsui Lab, “Manga109: Japanese Manga Dataset.” Accessed Sep. 27, 2024. [Online]. Available: http://www.manga109.org/en/annotations.html<\p>
[4] S. Reddy, “Pre-Processing in OCR!!!,” Medium, Jul. 24, 2020. https://towardsdatascience.com/pre-processing-in-ocr-fc231c6035a7<\p>
[5] N. K. Bjerregaard, V. Cheplygina, and S. Heinrich, Detection of furigana text in images, https://arxiv.org/pdf/2207.03960 (accessed Nov. 7, 2024). <\p>
[6] R. Smith, “An Overview of the Tesseract OCR Engine.” Available: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/33418.pdf<\p>
[7] S.-H. Tsang, “Review: Resnet - winner of ILSVRC 2015 (Image Classification, localization, detection),” Medium, https://towardsdatascience.com/review-resnet-winner-of-ilsvrc-2015-image-classification-localization-detection-e39402bfa5d8 (accessed Nov. 7, 2024).<\p>
[8] K. He, J. Sun, S. Ren, and X. Zhang, Arxiv, https://arxiv.org/pdf/1512.03385v1 (accessed Nov. 7, 2024).<\p>
[9] A. Dosovitskiy et al., “AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE,” arXiv.org, https://arxiv.org/pdf/2010.11929 (accessed Nov. 7, 2024<\p>
[10] zyddnys, “Image/Manga Translator,” GitHub, Aug. 08, 2023. https://github.com/zyddnys/manga-image-translator<\p>
[11] Nikolaj Kjøller Bjerregaard, Veronika Cheplygina, and Stefan Heinrich, “Detection of Furigana text in images” arXiv.org, Jul. 2022, https://arxiv.org/pdf/2207.03960<\p>
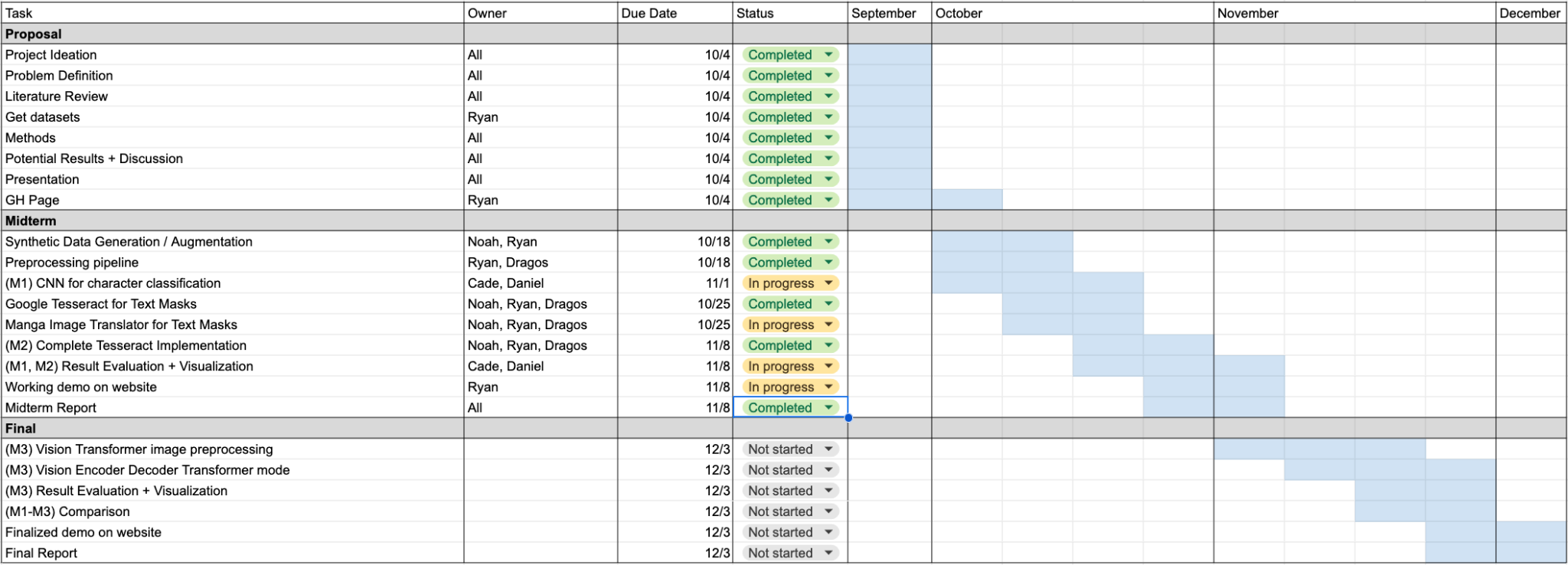
GANTT CHART
CONTRIBUTION TABLE
| Name | Primary Contributions |
|---|---|
| Ryan | Tesseract Implementation + Results, Website |
| Noah | Data Generation |
| Dragos | Preprocessing Pipeline |
| Cade | Literature Review, Tesseract Visualization |
| Daniel | Literature Review |